Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系

我们将在24小时内删除
友情链接: 网站地图
转载自【菜J学Python】:用Python实现《沉默的真相》3万+弹幕情感分析
大家好,我是J哥。
以前我写过不少文本数据分析,比如《八佰》影评分析、《三十而已》热评分析等,但基本停留在可视化分析层面。本文将运用文本挖掘技术,对最近热播剧《沉默的真相》弹幕数据进行深入分析,希望对大家有一定的启发。
本文数据分析思路及步骤如下图所示,阅读本文需要10min,您可在「菜J学Python」公众号后台回复文本挖掘获取弹幕数据进行测试。
《沉默的真相》共12集,分集爬取,共生成12个csv格式的弹幕数据文件,保存在danmu文件夹中。通过glob方法遍历所有文件,读取数据并追加保存到danmu_all文件中。
csv_list = glob.glob('/菜J学Python/danmu/*.csv') print('共发现%s个CSV文件'% len(csv_list)) print('正在处理............') for i in csv_list: fr = open(i,'r').read() with open('danmu_all.csv','a') as f: f.write(fr) print('合并完毕!')清洗后数据如下所示:
机械压缩去重即数据句内的去重,我们发现弹幕内容存在例如"啊啊啊啊啊"这种数据,而实际做情感分析时,只需要一个“啊”即可。

情感分析是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑。目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。
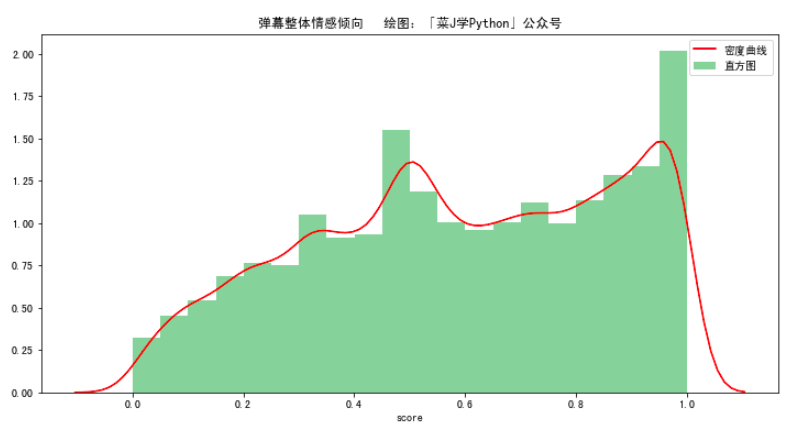
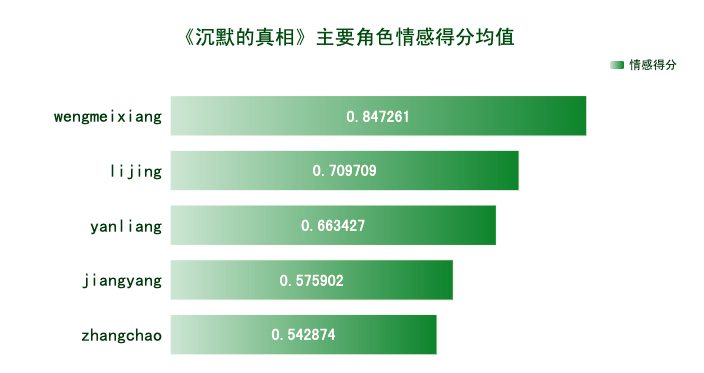
本文主要运用Python的第三方库SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。
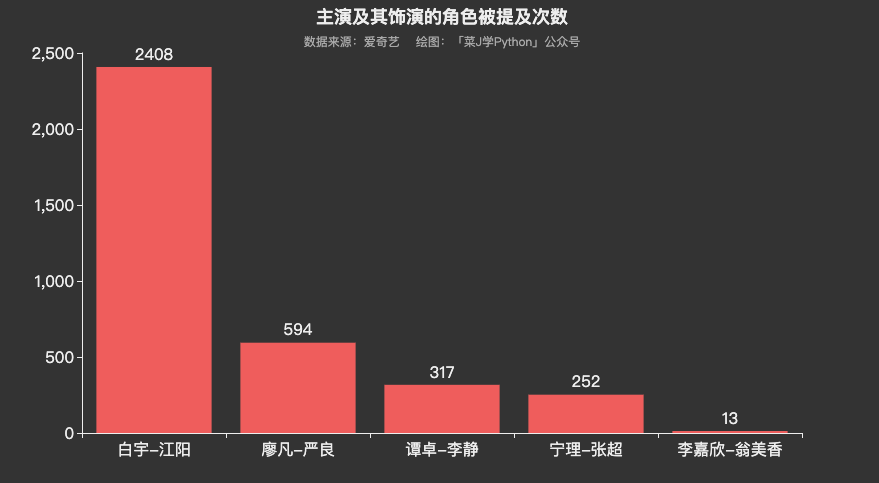
由各主要角色情感得分均值可知,观众对他们都表现出积极的情感。翁美香和李静的情感得分均值相对高一些,难道是男性观众偏多?江阳的情感倾向相对较低,可能是观众对作为正义化身的他惨遭各种不公而鸣不平吧。
首先,筛选出两大类分别进行分词。
本文来源:https://www.kandian5.com/articles/30362.html

徐无鬼因女商见魏武侯,武侯劳之曰:“先生病矣,苦于山林之劳,故乃肯见于寡人。”徐无鬼曰:“我则劳于君,君有何劳于我!君将盈耆欲,长好恶,则性命之情病矣;君将黜耆欲,牵好恶,则耳目病矣。我将劳君,君有何...

“让王”,意思是禅让王位。本篇文章的主旨在于阐述重生,提倡不因外物妨碍生命的思想。利禄不可取,王位可以让,全在于看重生命,保全生命。“轻物重生”的观点历来多有指斥,认为与庄子思想不合,但其间亦有相通之...

世宗贤妃墓,又称“世宗贤妃坟”、"世宗六妃、二太子墓"或“四妃、二太子墓”。是明十三陵的7座妃嫔墓之一。内葬有郑贤妃等至少四位妃子、二位太子。墓园简介位于神宗四妃墓及悼陵之间,俗称"小宫"。坟园坐北朝...

“徐无鬼”是开篇的人名,以人名作为篇名。全篇大体可分为十四个部分。第一部分至“莫以真人之言謦吾君之侧乎”,写徐无鬼拜见魏武侯,用相马之术引发魏武侯的喜悦,借此讥讽诗、书、礼、乐的无用。第二部分至“君将...

《庄子·杂篇·庚桑楚》:“庚桑楚”是首句里的一个人名,这里以人名为篇名。全篇涉及许多方面的内容,有讨论顺应自然倡导无为的,有讨论认知的困难和是非难以认定的,但多数段落还是在讨论养生。全文大体可以分为五...

知向北游历来到玄水岸边,登上名叫隐弅的山丘,正巧在那里遇上了无为谓。知对无为谓说:“我想向你请教一些问题:怎样思索、怎样考虑才能懂得道?怎样居处、怎样行事才符合于道?依从什么、采用什么方法才能获得道?...

老聃之役有庚桑楚者,偏得老聃之道,以北居畏垒之山。其臣之画然知者去之,其妾之挈然仁者远之。拥肿之与居,鞅掌之为使。居三年,畏垒大壤。畏垒之民相与言曰:“庚桑子之始来,吾洒然异之。今吾日计之而不足,岁计...

《庄子》是战国时期著名思想家庄周的毕生精华之作,《知北游》是《庄子·外篇》中的最后一篇,也是具有重要地位的一篇,对于了解《庄子》的哲学思想体系也较为重要。本篇是“外篇”的最后一篇,以篇首的三个字作为篇...

知北游于玄水之上,登隐弅之丘,而适遭无为谓焉。知谓无为谓曰:“予欲有问乎若:何思何虑则知道?何处何服则安道?何从何道则得道?”三问而无为谓不答也。非不答,不知答也。知不得问,反于白水之南,登狐阕之上,...

田子方是篇首的人名。全篇内容比较杂,具有随笔、杂记的特点,不过从一些重要章节看,主要还是表现虚怀无为、随应自然、不受外物束缚的思想。全文自然分成长短不一、各不相连的十一个部分,第一部分至“夫魏真为我累...
Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系
我们将在24小时内删除
友情链接: 网站地图