Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系

我们将在24小时内删除
友情链接: 网站地图

作者:J哥
源自:菜J学Python
本文将运用文本挖掘技术,对最近热播剧《沉默的真相》弹幕数据进行深入分析,希望对大家有一定的启发。
本文数据分析思路及步骤如下图所示,阅读本文需要10min,您可在「快学Python」公众号后台回复文本挖掘获取弹幕数据进行测试。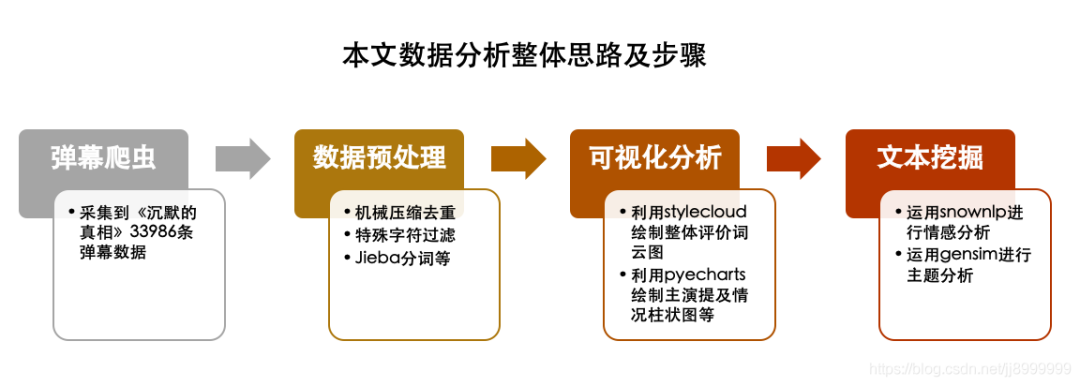
本文仅提供核心代码:
from xml.dom.minidom import parse《沉默的真相》共12集,分集爬取,共生成12个csv格式的弹幕数据文件,保存在danmu文件夹中。通过glob方法遍历所有文件,读取数据并追加保存到danmu_all文件中。
csv_list = glob.glob('/菜J学Python/danmu/*.csv')
机械压缩去重即数据句内的去重,我们发现弹幕内容存在例如"啊啊啊啊啊"这种数据,而实际做情感分析时,只需要一个“啊”即可。
应用以上函数,对弹幕内容进行句内去重。
df["danmu"] = df["danmu"].apply(yasuo)另外,我们还发现有些弹幕内容包含表情包、特殊符号等,这些脏数据也会对情感分析产生一定影响。

特殊字符直接通过正则表达式过滤,匹配出中文内容即可。
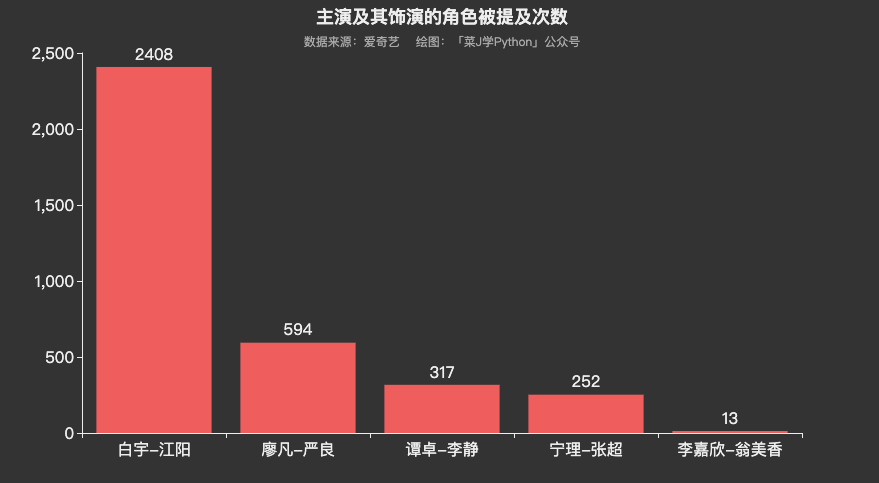
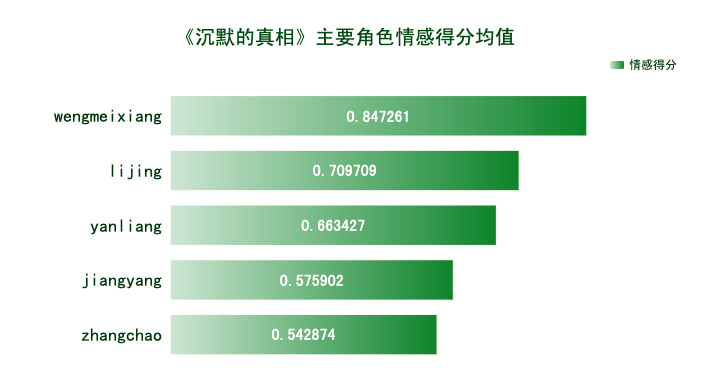
数据可视化分析部分代码本公众号往期原创文章已多次提及,本文不做赘述。从可视化图表来看,网友对《沉默的真相》还是相当认可的,尤其对白宇塑造的正义形象江阳,提及频率远高于其他角色。

情感分析是对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。其中,前者多用于舆情监控和信息预测,后者可帮助用户了解某一产品在大众心目中的口碑。目前常见的情感极性分析方法主要是两种:基于情感词典的方法和基于机器学习的方法。
本文主要运用Python的第三方库SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率,越接近0情感表现越消极,越接近1情感表现越积极。
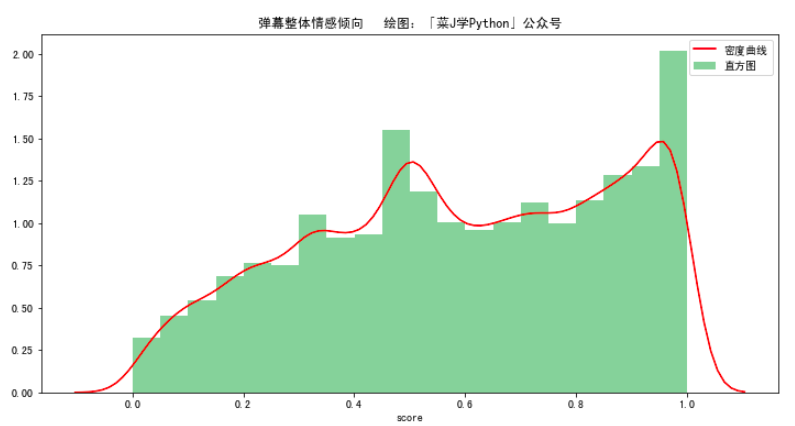
这里的主题分析主要是将弹幕情感得分划分为两类,分别为积极类(得分在0.8以上)和消极类(得分在0.3以下),然后再在各类里分别细分出5个主题,有助于挖掘出观众情感产生的原因。
首先,筛选出两大类分别进行分词。
#分词本文来源:https://www.kandian5.com/articles/30376.html

贾敬,中国古典小说曹雪芹写的《红楼梦》中的人物,宁国公贾演的孙子,京营节度使世袭一等神威将军贾代化的次子,京营节度使世袭一等神威将军贾代化的次子,贾珍之父。是丙辰科进士,一味好道,在都外玄贞观修炼,烧...

宁国府是《红楼梦》中宁国公的府邸。宁国府作为一级地方府始于南宋乾道二年(公元1166年),在此之前又名宣州、宣城郡、宁国军。而《红楼梦》里面所写的宁国府,是贾府里面的一府,另一府为荣国府,宁国府是高于...

《小髻》是清代小说家蒲松龄创作的文言短篇小说。狐对长山居民说,过几天就会搬来和他做邻居。狐不会想到,这句话几乎带来灭门之灾。狐大概以为,人会善待邻居,远亲不如近邻。甚至可能天真的认为,还会“各复延至其...

在当下,很多历史类畅销读物都千篇一律从皇帝、权臣的视角来看待古代社会,从平民视角看待社会的作品少之又少,以至于很多人对古人的生活条件有所误判,认为人人在古代都可以三妻四妾、有下人伺候。那么,古代平民生...

《蛰龙》是清代小说家蒲松龄创作的文言短篇小说。曲迁乔,号带溪,周村黄家渡口庄人。家中原来略有田产,后来逐渐败落,父亲是穷书生,只能维持温饱。曲迁乔自幼喜欢读书,但年纪很大了才考中举人。1577年(明万...

《戏术》是清代小说家蒲松龄创作的一篇小说。故事概要《戏术》古代俗称“戏法”,在现在称为“魔术”。此文由两个简短的小故事组成,虽然短,却像麻雀一样五应俱全,描写得非常到位,这也充分展现了蒲松龄的写作功底...

近年来,日本各大影楼盛行和服体验,其中最受欢迎的便是花魁系列。虽然现在的日本不再有花魁,然而花魁的形象仍然影响着现今的日本文化。那么花魁到底是怎样的一种存在呢? 花魁(日语读:おいらん)是指日本江户时...

由于历史原因,二战后日本警察无法管理日本治安需要黑帮力量维持社会运行,因此承认日本黑社会的社会地位,世界上只此一例。今天日本黑社会已经脱离了血淋淋的原始资本积累时期,90年代以后的日本黑社会不会直接参...

《江中》是清代小说家蒲松龄创作的文言短篇小说。本文选自朱其铠主编的《全本新注聊斋志异》卷三。本文主要内容是,王圣俞在江的中心遇见的鬼神,常常于夜里在船只附近出没,忽隐忽现给人一种诡异的感觉。原文王圣俞...

食物,是人类维持正常生活所需要的物品,没有食物的话,人类是没有办法长久生存的,而肉类,也是一项很重要的能量来源,现代很多时候并没有什么禁忌,但是在古代,吃肉也有很多禁忌,在中国是这样,古代的日本也是这...
Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系
我们将在24小时内删除
友情链接: 网站地图