Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系

我们将在24小时内删除
友情链接: 网站地图
原标题:Python爬《沉默的真相》3万+弹幕,告诉你这剧到底“香”在哪?
文末扫海报二维码领【本文代码】
J哥 | 作者
菜J学Python | 来源
https://mp.weixin.qq.com/s/le-jsfCEZgfhfyeCwQPmEQ
本文运用文本挖掘技术,对最近热播剧《沉默的真相》3万+弹幕进行数据分析,希望对你有一定的启发。
本文数据分析思路及步骤如下图所示,阅读本文需要10min,你可添加小数获取弹幕数据进行测试。
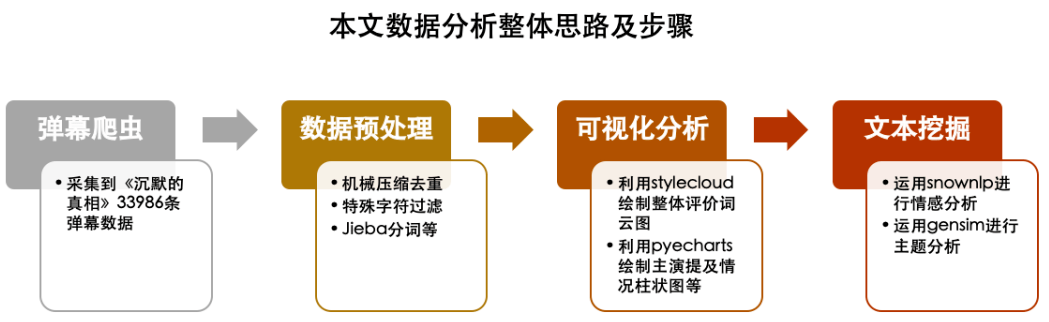
1
数据获取
本文仅提供核心代码:
fromxml.dom.minidom importparse
importxml.dom.minidom
defxml_parse(file_name):
DOMTree = xml.dom.minidom.parse(file_name)
collection = DOMTree.documentElement
# 在集合中获取所有entry数据
entrys = collection.getElementsByTagName( "entry")
print(entrys)
result = []
forentry inentrys:
content = entry.getElementsByTagName( 'content')[ 0]
print(content.childNodes[ 0].data)
i = content.childNodes[ 0].data
name = entry.getElementsByTagName( 'name')[ 0]
print(name.childNodes[ 0].data)
j = name.childNodes[ 0].data
dd = [j,i]
result.append(dd)
print(result)
returnresult
2
数据清洗
1.导入数据分析库
#数据处理库
importnumpy asnp
importpandas aspd
importglob
importre
importjieba
#可视化库
importstylecloud
importmatplotlib.pyplot asplt
importseaborn assns
%matplotlib inline
frompyecharts.charts import*
frompyecharts importoptions asopts
frompyecharts.globals importThemeType
fromIPython.display importImage
#文本挖掘库
fromsnownlp importSnowNLP
fromgensim importcorpora,models
2.合并弹幕数据
《沉默的真相》共12集,分集爬取,共生成12个 csv格式的弹幕数据文件,保存在 danmu文件夹中。通过 glob方法遍历所有文件,读取数据并追加保存到 danmu_all文件中。
csv_list = glob. glob( '/菜J学Python/danmu/*.csv')
print( '共发现%s个CSV文件'% len(csv_list))
print( '正在处理............')
fori in csv_lis t:
fr = open(i, 'r'). read
with open( 'danmu_all.csv', 'a') asf:
f. write(fr)
print( '合并完毕!')
3.重复值、缺失值等处理
#error_bad_lines参数可忽略异常行
df = pd.read_csv( "./danmu_all.csv",header= None,error_bad_lines= False)
df = df.iloc[:,[ 1, 2]] #选择用户名和弹幕内容列
df = df.drop_duplicates #删除重复行
df = df.dropna #删除存在缺失值的行
df.columns = [ "user", "danmu"] #对字段进行命名
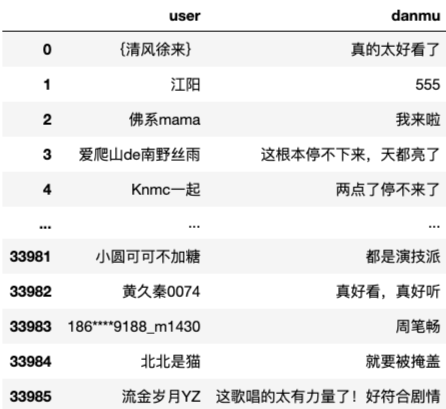
df
清洗后数据如下所示:
4.机械压缩去重
机械压缩去重即 数据句内的去重,我们发现弹幕内容存在例如"啊啊啊啊啊"这种数据,而实际做情感分析时,只需要一个“啊”即可。

#定义机械压缩去重函数
def yasuo( st):
fori in range( 1, int( len( st)/ 2)+ 1):
forjin range( len( st)):
ifst[ j: j+i] == st[ j+i: j+ 2*i]:
k= j+ i
whilest[ k: k+i] == st[ k+i: k+ 2*i] andk< len( st):
k= k+ i
st= st[: j] + st[ k:]
returnst
yasuo( st= "啊啊啊啊啊啊啊")
应用以上函数,对弹幕内容进行句内去重:
df[ "danmu"] = df[ "danmu"].apply(yasuo)
5.特殊字符过滤
另外,我们还发现有些弹幕内容包含 表情包、特殊符号等,这些脏数据也会对情感分析产生一定影响。

特殊字符直接通过正则表达式过滤, 匹配出中文内容即可。
df[ 'danmu'] = df[ 'danmu'].str.extract( r"([u4e00-u9fa5]+)")
df = df.dropna #纯表情直接删除
另外, 过短的弹幕内容一般很难看出情感倾向,可以将其一并过滤。
df= df[df[ "danmu"].apply(len)>= 4]
df= df.dropna
3
数据可视化
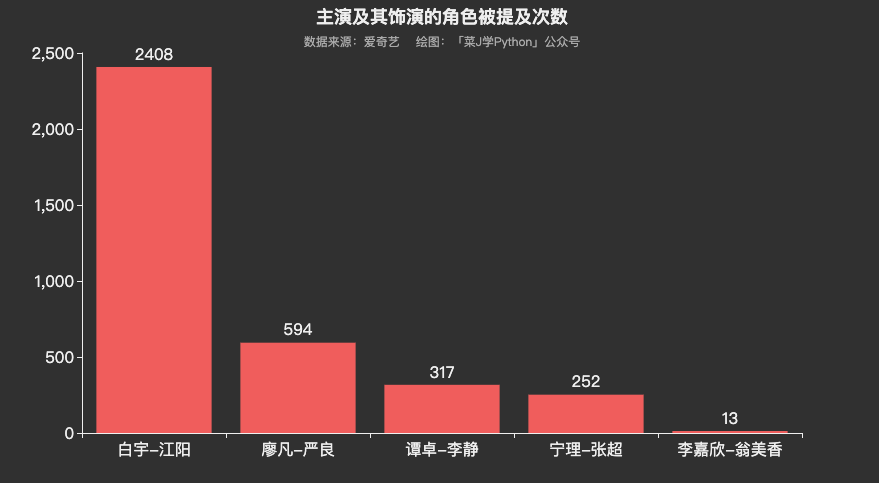
从 可视化图表来看,网友对《沉默的真相》还是相当认可的,尤其对白宇塑造的正义形象江阳,提及频率远高于其他角色。
1.整体弹幕词云

2.主演提及
4
文本挖掘(NLP)
1.情感分析
情感分析是 对带有感情色彩的主观性文本进行分析、处理、归纳和推理的过程。按照处理文本的类别不同,可分为基于 新闻评论的情感分析和基于 产品评论的情感分析。
其中,前者多用于 舆情监控和信息预测,后者可帮助用户 了解某一产品在大众心目中的口碑。目前常见的情感极性分析方法主要是两种:基于 情感词典的方法和基于 机器学习的方法。
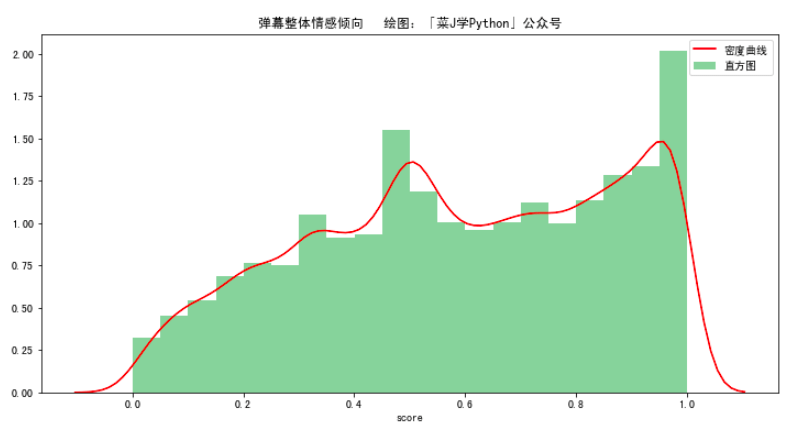
本文主要运用Python的第三方库 SnowNLP对弹幕内容进行情感分析,使用方法很简单,计算出的情感score表示语义积极的概率, 越接近0情感表现越消极,越接近1情感表现越积极。
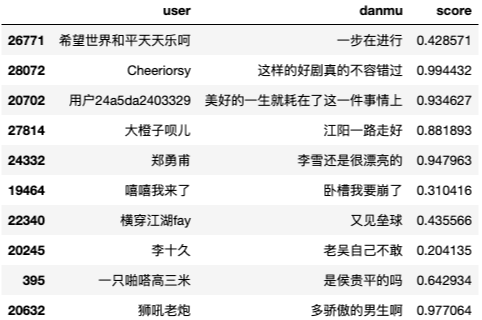
df[ 'score'] = df[ "danmu"].apply( lambdax:SnowNLP(x).sentiments)
df.sample( 10) #随机筛选10个弹幕样本数据
(1)整体情感倾向
plt.rcParams[ 'font.sans-serif'] = [ 'SimHei'] # 设置加载的字体名
plt.rcParams[ 'axes.unicode_minus'] = False# 解决保存图像是负号'-'显示为方块的问题
plt.figure(figsize=( 12, 6)) #设置画布大小
rate = df[ 'score']
ax = sns.distplot(rate,
hist_kws={ 'color': 'green', 'label': '直方图'},
kde_kws={ 'color': 'red', 'label': '密度曲线'},
bins= 20) #参数color样式为salmon,bins参数设定数据片段的数量
ax.set_title( "弹幕整体情感倾向 绘图:「菜J学Python」公众号")
plt.show
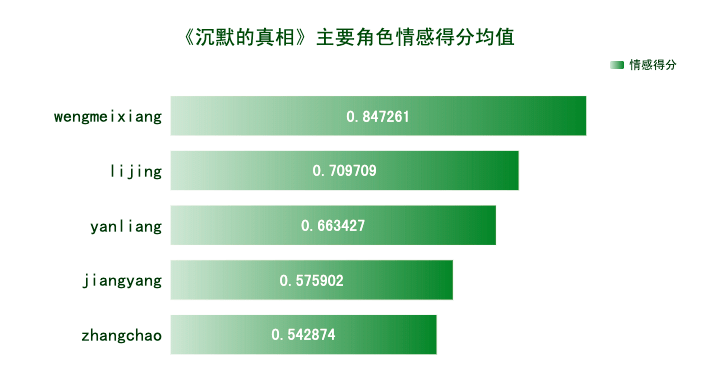
(2)观众对主演的情感倾向
mapping = { 'jiangyang': '白宇|江阳', 'yanliang': '廖凡|严良', 'zhangchao': '宁理|张超', 'lijing': '谭卓|李静', 'wengmeixiang': '李嘉欣|翁美香'}
forkey, value in mapping. items:
df[key] = df[ 'danmu'].str.contains(value)
average_value = pd.Series({key: df. loc[df[key], 'score'].mean forkey in mapping. keys})
print(average_value.sort_values)
由各 主要角色情感得分均值可知,观众对他们都表现出积极的情感。翁美香和李静的情感得分均值相对高一些,难道是男性观众偏多?江阳的情感倾向相对较低,可能是观众对作为正义化身的他惨遭各种不公而鸣不平吧。
2.主题分析
这里的主题分析主要是将弹幕情感得分划分为两类,分别为 积极类(得分在0.8以上)和 消极类(得分在0.3以下),然后再在各类里分别细分出5个主题,有助于挖掘出观众情感产生的原因。
首先, 筛选出两大类分别进行分词:
#分词
data1 = df[ 'danmu'][ df["score"]>=0.8]
data2 = df[ 'danmu'][ df["score"] < 0.3]
word_cut= lambdax:' ' .join( jieba.cut( x)) #以空格隔开
data1= data1.apply(word_cut)
data2= data2.apply(word_cut)
print( data1)
print(' ----------------------')
print( data2)
然后, 分别去除停用词:
#去除停用词
stop = pd.read_csv( "/菜J学Python/stop_words.txt",encoding= 'utf-8',header= None,sep= 'tipdm')
stop = [ ' ', ''] + list(stop[ 0])
#print(stop)
pos = pd.DataFrame(data1)
neg = pd.DataFrame(data2)
pos[ "danmu_1"] = pos[ "danmu"].apply( lambdas:s.split( ' '))
pos[ "danmu_pos"] = pos[ "danmu_1"].apply( lambdax:[i fori inx ifi.encode( 'utf-8') notinstop])
#print(pos["danmu_pos"])
neg[ "danmu_1"] = neg[ "danmu"].apply( lambdas:s.split( ' '))
neg[ "danmu_neg"] = neg[ "danmu_1"].apply( lambdax:[i fori inx ifi.encode( 'utf-8') notinstop])
接着, 对积极类弹幕进行主题分析:
#正面主题分析
pos_dict = corpora.Dictionary(pos[ "danmu_pos"]) #建立词典
#print(pos_dict)
pos_corpus = [pos_dict.doc2bow(i) fori inpos[ "danmu_pos"]] #建立语料库
pos_lda = models.LdaModel(pos_corpus,num_topics=5,id2word=pos_dict) #LDA模型训练
print( "正面主题分析:")
fori inrange(5):
print( 'topic',i+1)
print(pos_lda.print_topic(i)) #输出每个主题
print( '-'*50)
结果如下:

最后, 对消极类弹幕进行主题分析:
#负面主题分析
neg_dict = corpora.Dictionary(neg[ "danmu_neg"]) #建立词典
#print(neg_dict)
neg_corpus = [neg_dict.doc2bow(i) fori inneg[ "danmu_neg"]] #建立语料库
neg_lda = models.LdaModel(neg_corpus,num_topics=5,id2word=neg_dict) #LDA模型训练
print( "负面面主题分析:")
forj inrange(5):
print( 'topic',j+1)
print(neg_lda.print_topic(j)) #输出每个主题
print( '-'*50)
结果如下:

5
总结
本文较为系统的分析了 《沉默的的真相》3万+弹幕数据,但由于 snownlp对商品评论做文本挖掘更有效,您也可以尝试用 百度AI和腾讯AI进行情感分析,分析的结果可能更准确一些。
本文来源:https://www.kandian5.com/articles/30378.html

【原文】夫以勇事人者,以死也。未死而言死,不论①。以虽知之,与勿知同②。凡智之贵也,贵知化也。人主之惑者则不然。化未至则不知;化已至,虽知之,与勿知一贯也③。事有可以过者④,有不可以过者。而身死国亡,...

【原文】贤主所贵莫如士。所以贵士,为其直言也。言直则枉者见矣。人主之患,欲闻枉而恶直言,是障其源而欲其水也,水奚自至?是贱其所欲而贵其所恶也②,所欲奚自来?能意见齐宣王。宣王曰:“寡人闻子好直,有之乎...

【原文】言极①则怒,怒则说者危。非贤者孰肯犯危?而非贤者也,将以要②利矣;要利之人,犯危何益?故不肖主无贤者。无贤则不闻极言,不闻极言,则奸人比周,百邪悉起。若此则无以存矣。凡国之存也,主之安也,必有...

当年赵文王喜好剑术,击剑的人蜂拥而至门下食客三千余人,在赵文王面前日夜相互比试剑术,死伤的剑客每年都有百余人,而赵文王喜好击剑从来就不曾得到满足。像这样过了三年,国力日益衰退,各国诸侯都在谋算怎样攻打...

昔赵文王喜剑,剑士夹门而客三千余人,日夜相击于前,死伤者岁百余人,好之不厌。如是三年,国衰。诸侯谋之。太子悝患之,募左右曰:“孰能说王之意止剑士者,赐之千金。”左右曰:“庄子当能。”太子乃使人以千金奉...

《说剑》以义名篇,内容就是写庄子说剑。赵文王喜欢剑,整天与剑士为伍而不料理朝政,庄子前往游说。庄子说剑有三种,即天子之剑,诸侯之剑和庶民之剑,委婉地指出赵文王的所为实际上是庶民之剑,而希望他能成为天子...

孔子与柳下季为友,柳下季之弟名曰盗跖。盗跖从卒九千人,横行天下,侵暴诸侯。穴室枢户,驱人牛马,取人妇女。贪得忘亲,不顾父母兄弟,不祭先祖。所过之邑,大国守城,小国入保,万民苦之。孔子谓柳下季曰:“夫为...

孔子跟柳下季是朋友,柳下季的弟弟名叫盗跖。盗跖的部下有九千人,横行天下,侵扰各国诸侯;穿室破门,掠夺牛马,抢劫妇女;贪财妄亲,全不顾及父母兄弟,也不祭祀祖先。他所经过的地方,大国避守城池,小国退入城堡...

《史记》用精练的几行字介绍了庄子,说他著书十余万言,大抵都是寓言,如其中的《渔父》、《盗跖》、《胠箧》等篇,都是用来攻击孔子的学说,从而辨明老子的主张的。共三十三篇,分“内篇”、“外篇”、“杂篇”三个...

尧把天下让给许由,许由不接受。又让给子州支父,子州支父说:“让我来做天子,那还是可以的。不过,我正患有很深、很顽固的病症,正打算认真治一治,没有空闲时间来治天下。”统治天下是地位最高、权力最重的了,却...
Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系
我们将在24小时内删除
友情链接: 网站地图