Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系

我们将在24小时内删除
友情链接: 网站地图
参考: B站_葩葩数据_2021年4月流量明星百度搜索指数动态排名.
小姐姐讲的非常好,希望多多关注、点赞。
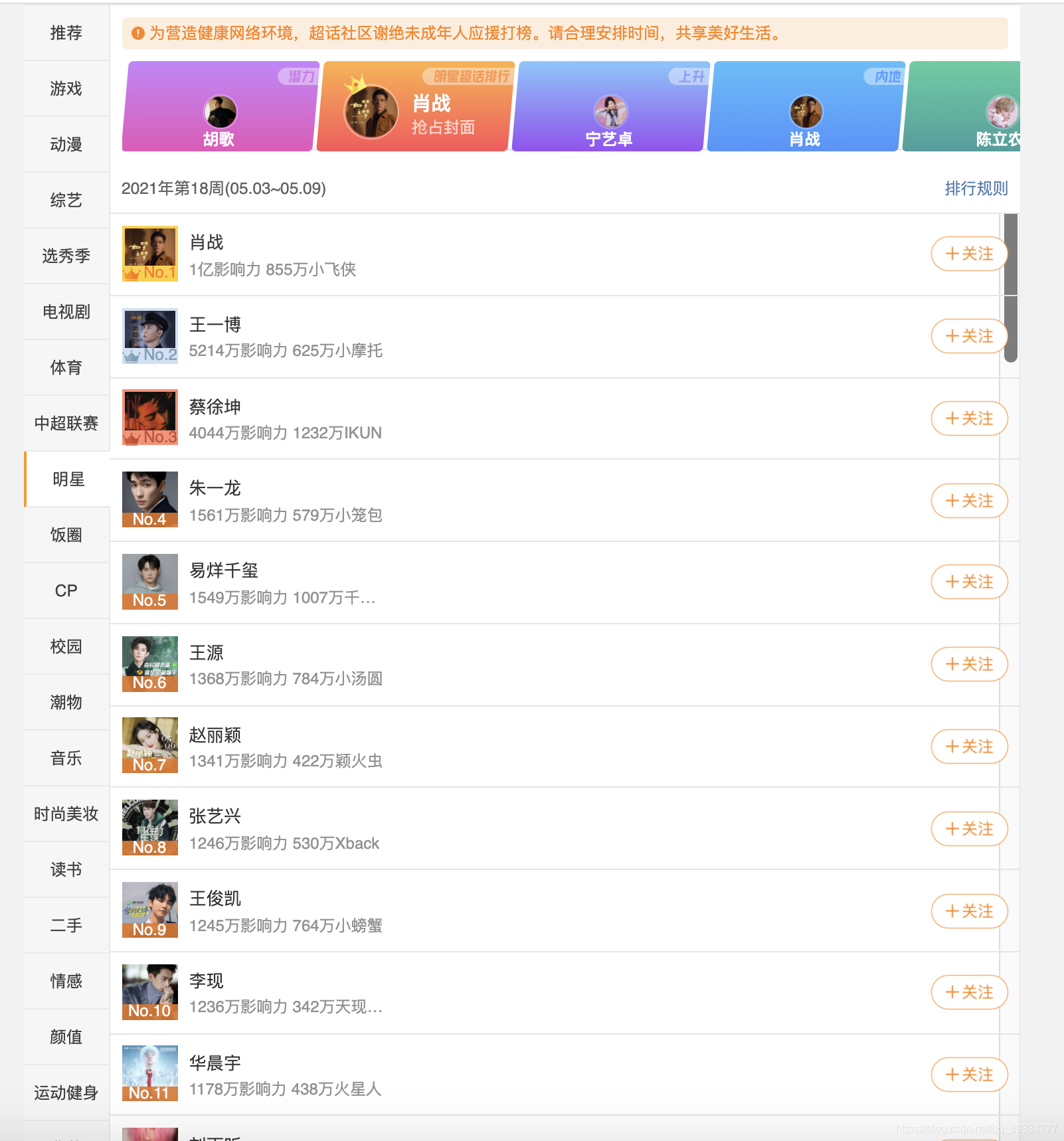
运行结果:
将生成的表格导入flourish中,效果图如下图所示: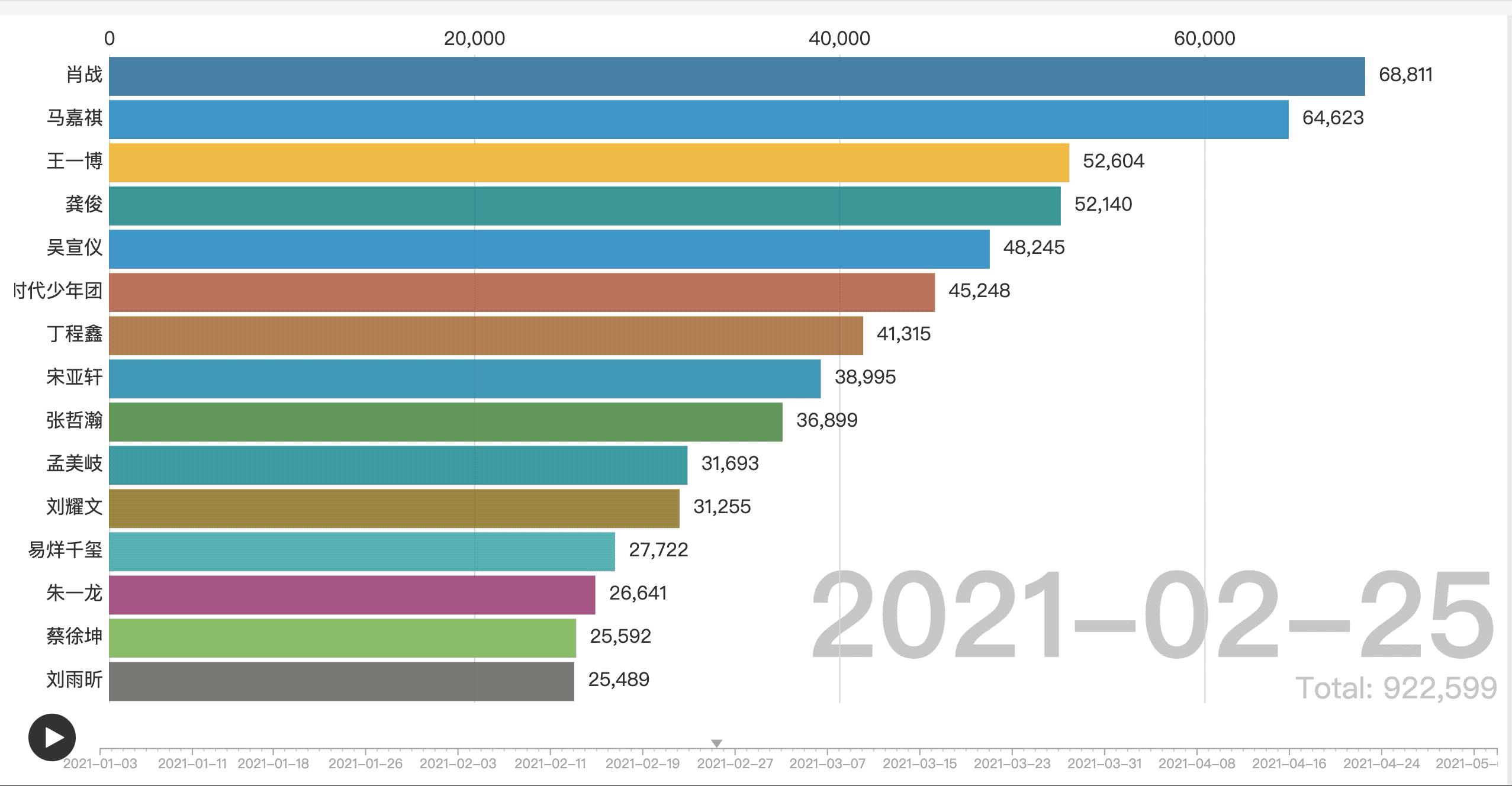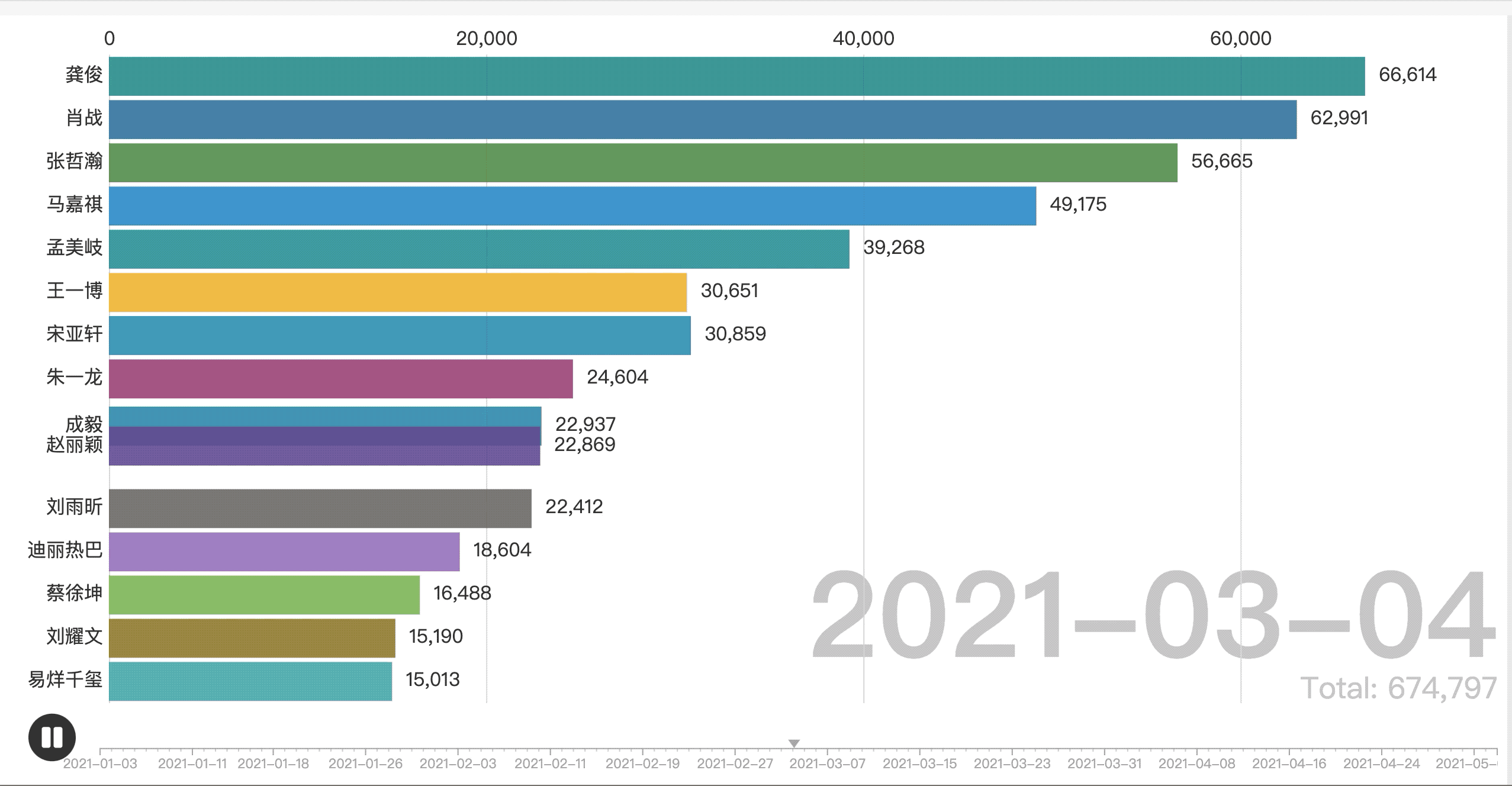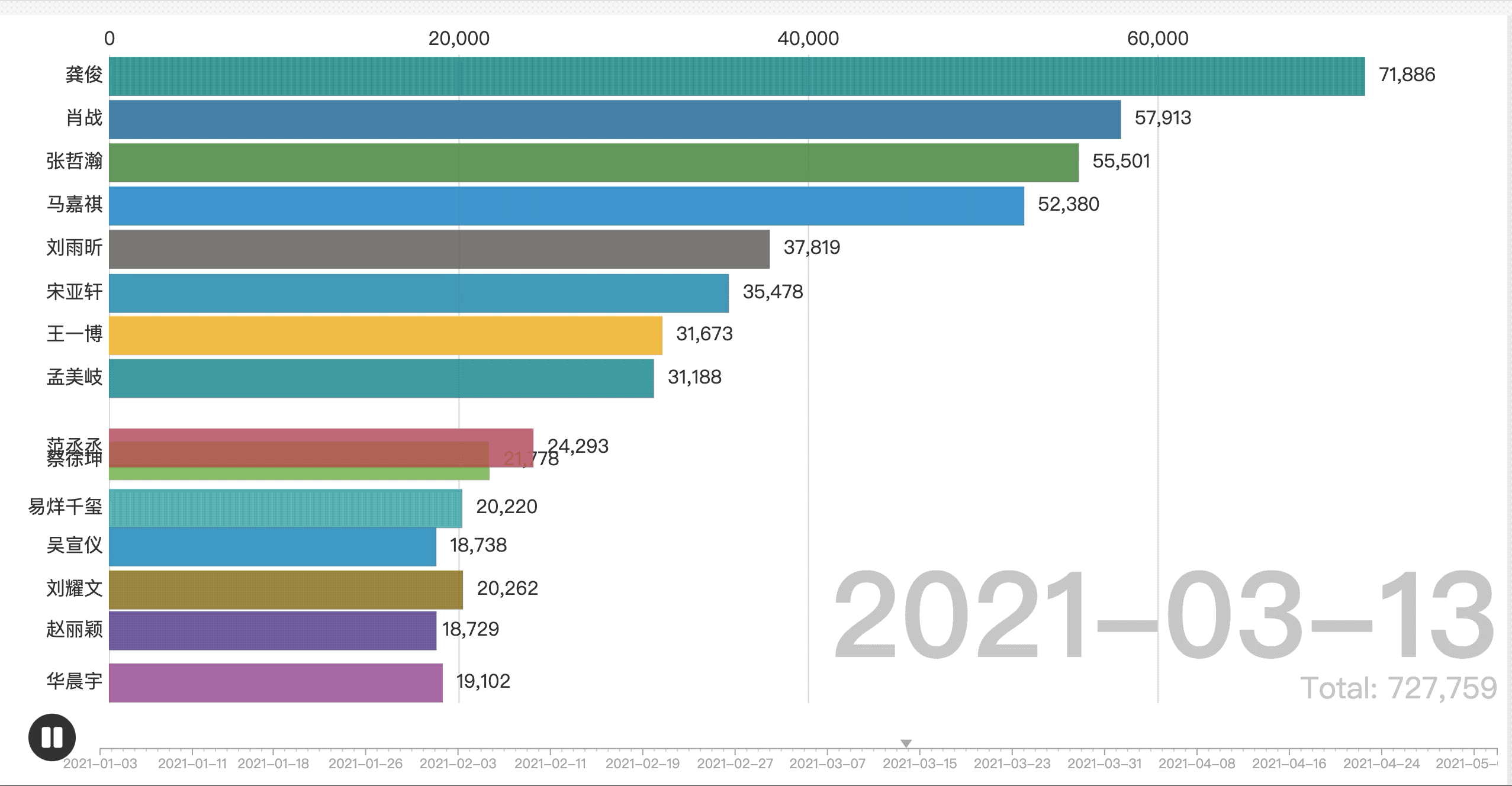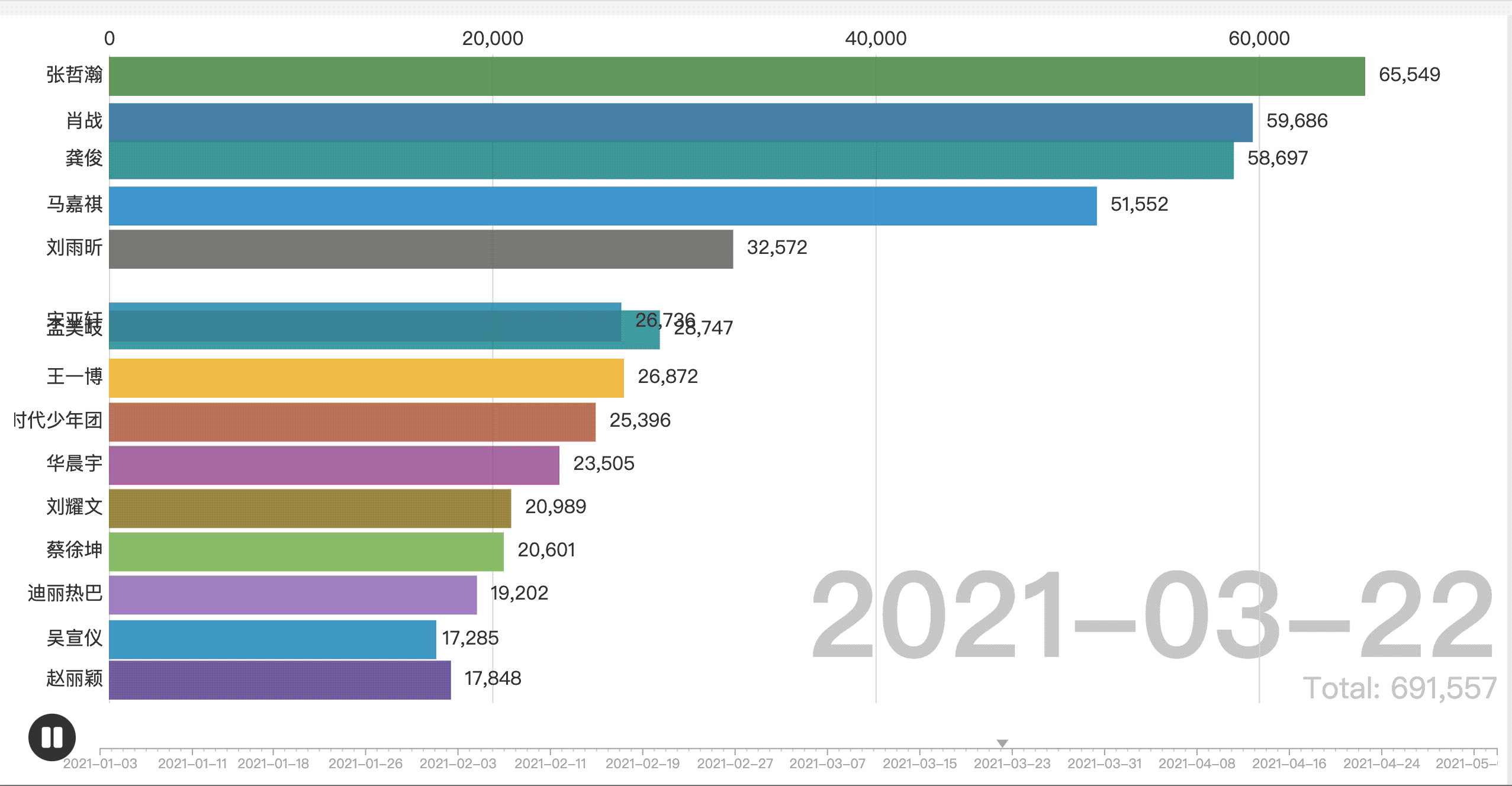
本文来源:https://www.kandian5.com/articles/3048.html

阴道分泌物,一般指「白带」,正常呈白色或透明。在孕期出现褐色分泌物,一般是由阴道出血、宫腔胚胎异常或是胎盘异常出血等引起,由于分泌物在阴道停留时间长、排出较晚,就会变成褐色。妊娠期一般分为三个阶段,妊...
自古以来,胎梦就被视为预测胎儿性别和未来发展的重要线索。许多准妈妈在怀孕期间会做各种奇特的梦,其中 梦见小鸟、白色羽毛和晨露 等意象尤为常见,且常被民间解读为可能预示生女孩的征兆。这些梦境究竟蕴含着怎...

从古至今,胎梦一直被准父母们视为预测宝宝性别与未来发展的重要线索。本文将深入解析梦见 花卉、水果、水 等常见意象与生女孩之间的神秘联系,为您提供一份详尽的胎梦指南。一、胎梦文化背景与科学认知胎梦,即...

关于生女孩的胎梦,传统解读中往往与 柔和、纯净、优雅的意象 相关联。月亮代表阴柔之美,花朵象征生命的绽放,水元素寓意温柔如水,这些都在文化符号学中与女性特质紧密相连。而现代心理学则认为,这些梦境可能反...

在东亚传统文化中,胎梦一直被视为预测胎儿性别和未来命运的重要征兆。当准妈妈们梦见 皎洁的月亮、晶莹的珍珠或翩翩的蝴蝶时,常常会听到"这可能是怀女孩的征兆"的说法。这些美丽而温柔的梦境意象,为何会与女孩...

在备孕和怀孕期间,许多准父母都会经历各种奇妙的梦境,其中 "梦见蝴蝶" 常被认为与生女孩有关。这种关联不仅存在于中国民间传统中,在世界各地的文化里也有着丰富的解读。本文将从 心理学科学视角 和 民间传...

自古以来,胎梦就被视为预测胎儿性别和未来发展的重要征兆。许多准父母在怀孕期间都会经历各种生动奇特的梦境,这些梦境往往被赋予特殊的含义。在传统文化中, 生女孩和生男孩的胎梦有着显著的区别 ,从梦境内容到...

河南有一个孕妈妈怀孕五周去社区医院做阴道B超,确定自己有没有怀孕。当时夫妻俩想到怀孕了都非常关注,所以两夫妻都去医院了。而这个孕妈妈的老公有吸烟的习惯,她就希望能跟医生说一下,让老公戒烟,而且她家里面...

虽然每一包香烟上面都写着‘吸烟有害健康’,但是抽烟的人感受到的是烟可以带给他快乐。比如饭后抽一根烟就感觉自己像是神仙一样;比如说在困的时候抽一根烟能够解乏;比如说在无聊的时候抽...

广东中山一位宝妈面对孩子头朝下摔下床后的做法在短视频平台获得了众多网友的称赞。一是她没有慌乱;二是处理方法十分科学,连不少专家都留言夸赞“妈妈的做法让孩子受到的伤害降到最低”、...

Copyright 2012-2021 今日看点 All rights reserved. 苏ICP备13052634号-10
声明: 本站部分内容来源网络,如果你是该内容的作者,并且不希望本站发布你的内容,请与我们联系
我们将在24小时内删除
友情链接: 网站地图